Your DNA contains the genetic blueprint necessary to not just build your body but to build the proteins and molecules that ensure your body’s functionality. DNA encodes RNA, RNA encodes proteins and voila, your body functions.
But the biological reality of this process is much more complex. The shapes, twists and entanglements of your DNA and RNA— their topology — influence their functionality and your health. Damage to DNA, like radiation exposure leading to double-strand breaks, can cause mutations that develop into diseases like cancer.
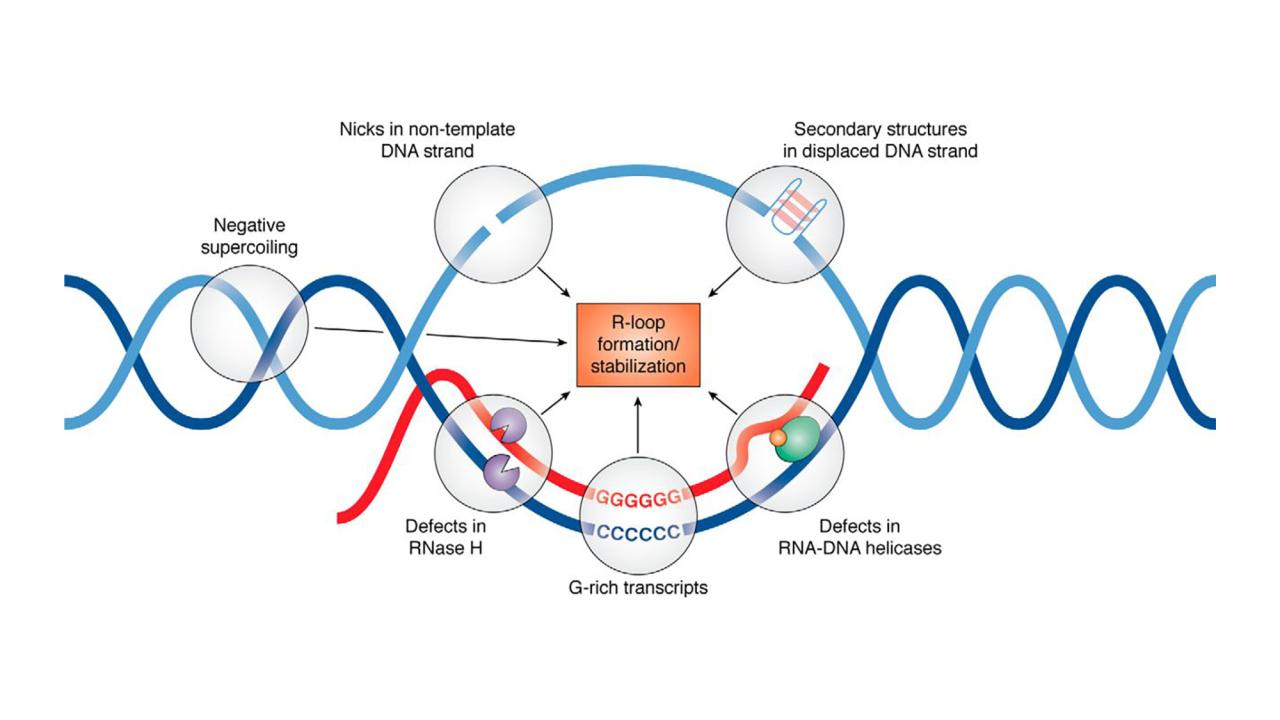
In a study appearing in PLOS Computational Biology, an interdisciplinary team led by UC Davis and University of South Florida researchers used data-driven analysis to investigate R-loops, which are impermanent, DNA-RNA hybrids that form during the DNA transcription process.
“R-loops help with the regulation of gene expression, but they have also been implicated in the production of double-stand breaks,” said study author Mariel Vázquez, a professor of mathematics, and microbiology and molecular genetics at UC Davis. “If you have a bunch of double-strand breaks that the cell cannot manage, that can lead to mutations and the development of cancers or other genetic diseases.”
Unraveling a mystery at the smallest scale
R-loops remain a biological mystery, but in the postgenomic era, scientists are gaining unprecedented views into this molecular realm thanks to genomics and computational biology methods.
In the study, Vázquez and her colleagues developed a computational model called the R-loop grammar, which uses formal language theory to accurately predict R-loop formation.
“We came up with a model based on formal languages where the ‘letters’ represent pieces of the R-loop,” said Vázquez, noting that the model accounts for the R-loop formation process from start to finish. “We have an alphabet and production rules, so we can produce ‘words.’ Each one of these ‘words’ is an R-loop.”
The team trained their R-loop grammar model on experimental data obtained using single-molecule RNA footprinting and sequencing (SMRF-seq). The SMRF-seq technique captures the positions and lengths of R-loops on a single DNA molecule at high resolution.
The experimental data contained 2,363 single-molecule reads with an R-loop present on each read. Specifically, the data included genetic information from two different plasmids (circular DNA molecules) that exhibited various topologies, or levels of coiling.
The team found that R-loop grammar successfully predicted R-loop formation for different topologies.
“After training with a portion of the data, our new R-loop grammar model achieved significantly higher precision than R-looper — a thermodynamics-based model that incorporates the effect of topology — reducing the prediction error by up to 55% and matching the experimental patterns twice as strongly,” Vázquez said. “Our model learns the effect of supercoiling directly from the data, although plasmid topology is not directly encoded into the formal language.”
A major success for R-loop grammar
For their next steps, the team wants to expand the DNA dataset being used to train R-loop grammar.
“If we train the model on larger and richer datasets, it will perform better,” Vázquez said. “The ultimate goal is to accurately predict R-loops for any sequence in a genome. So if you find a gene that’s implicated in some disease, the R-loop grammar would ideally be able to predict where an R-loop in that gene occurs.”
Additional authors include Margherita Maria Ferrari, Svetlana Poznanović, Manda Riehl, Jacob Lusk, Stella Hartono, Georgina Gonzalez-Isunza, Frédéric Chédin and Nataša Jonoska
The research reported on here was supported by the National Science Foundation, National Institutes of Health, W.M. Keck Foundation, Simons Foundation, and Natural Sciences and Engineering Research Council of Canada.
Media Resources
The R-loop grammar predicts R-loop formation under different topological constraints (PLOS Computational Biology)